聰明學統計的13又½堂課 Naked Statistics: Stripping the Dread from the Data
聰明學統計的13又½堂課
每個數據背後都有戲,搞懂才能做出正確判斷
Naked Statistics
Stripping the Dread from the Data
Charles Wheelan──著
愛荷──譯
先覺──出版
統計就像是高性能武器:
正確使用就有所幫助,錯誤使用就可能造成災難。
這本書不會讓你成為統計專家,但它會讓你對這個領域保有足夠的審慎及尊重。
換言之,這檔事你多少得懂一些,免得被炸死了,還不曉得自己是怎麼掛掉的。
博客來內容連載:前言
我愛統計,統計可以用來解釋從DNA檢驗到玩樂透的愚蠢行為;可以幫助我們辨識出和癌症、心臟病等疾病有關的因素;可以幫助我們觀察到標準測驗中的作弊行為,甚至可以幫助你在遊戲節目中獲勝。我小時候有個出名的節目叫做《讓我們做個交易》(Let's Make a Deal),它有個同樣有名的主持人蒙提.霍爾。在每一天節目的結尾,優勝者會站在蒙提旁邊,面對三扇大門:一號門、二號門,以及三號門。蒙提.霍爾會解釋有一扇門的後面是眾所企盼的獎品,例如一輛新車,其他兩扇門後面則是一隻羊。玩法很直截了當:優勝者選一扇門,就會獲得門後的獎品。
因為優勝者和主持人一起面對門,他有三分之一的機會選中那扇大獎的門,不過這個節目有一點變化,這點一直都讓統計學家覺得很有趣,同時也讓其他人覺得很困惑。當優勝者選擇一扇門之後,主持人會打開剩下兩扇門中的一扇,後面永遠是一隻羊。舉例來說,假設優勝者選了一號門,蒙提會打開三號門,就會看到一隻活生生的羊站在台上。其他一號門及二號門仍然關著。如果大獎是在一號門後,優勝者就贏了;如果大獎是在二號門後,優勝者就輸了。接下來,事情變得更有趣了:蒙提會問優勝者要不要改變心意,選擇另一扇門(在這個例子是從一號門改成二號門)。要記得這兩扇門都還是關著,優勝者唯一得到的新訊息是,他沒選的兩扇門中有一扇後面是一隻羊。
他應該換嗎?
答案是應該。本書的第5又½章會提到。
統計的弔詭是它們無所不在—從打擊率到總統民調都是—但是這門學問本身卻以無趣及難搞著稱。許多統計書籍與課程都充斥著數學與術語。相信我,技術細節非常重要且有趣,但是如果你不了解它的直覺,那統計對你來說就是希臘文了;而且如果你不相信有學習它的理由,那你連直覺也不用在乎了。本書的每一章都保證會回答我問過高中微積分老師的基本問題:學這個要做什麼?
這本書講的是直覺。它只簡短提到數學、方程式,以及圖形,而且我保證在提到時一定會有明確、啟發的目的。另一方面,這本書會費盡唇舌舉例說明,好讓你相信學習統計的確事關緊要。統計真的很有趣,而且大部分的內容並不難搞。
有一天,老師試著教我們將一組無限系列的總和匯集成一個有限數目的情況。一組無限系列指的是一個無止境的數字模式,例如1+½+¼+⋯…結尾的點點點表示這個模式持續到無限。
然後,我突然靈機一動。
想像你站在離牆剛好二呎的地方。
現在移離牆一半的距離(一呎),因此你現在距牆一呎遠。
從一呎開始,再移向離牆一半的距離(六吋,亦即二分之一呎);然後從六吋開始,再移一次(移三吋,亦即四分之一呎);然後再一次(移一又二分之一吋,亦即八分之一呎);然後再一次……
你會逐漸緊靠近牆(如當你離牆「一○二四分之一」吋時,再移向離牆一半的距離,亦即「二○四八分之一」吋),但你永遠不會撞到牆,因為就字面來說,你每次只移動離牆一半的距離。換句話說,你會無限接近牆,但永遠不會撞到它。如果我們用呎來計算你移動的距離,這個系列就可以這樣表示:1+½+¼+⋯⋯
道理就在這裡:雖然你會繼續移動前進,每一次移動都會讓你更靠近離牆一半的距離,但你移動的全部距離絕不會超過二呎,這正是你一開始離牆的距離。就數學而言,你移動的全部距離可以約略算是二呎,計算起來非常方便。數學家就會說這個無限系列(1+½+¼+⋯⋯)加總起來就是二呎,這就是老師那天想要教會我們的。
現在我已經證明統計的核心工具其實可以更合乎直覺與更易上手,接著我要提出一個看似相反的觀點:統計可能會過度容易上手,因為任何人只要有一台電腦和一些數據,敲幾下鍵盤,就可以完成複雜的統計過程。問題是如果數據不正確,或是不當使用統計技巧,結論就可能嚴重誤導,甚至造成危險。想像你在網路搜尋時,跳出下列這個假設性的新聞標題:工作時短暫休息的人更容易死於癌症。根據一項針對三萬六千名白領階級的驚人調查,那些習慣於上班時離開辦公室去休息十分鐘的員工,在未來五年內罹患癌症的可能性,要比上班時間不離開辦公室的員工高出百分之四十一。顯然我們針對這項發現應該採取一些行動,例如發起全國性運動來阻止工作時的短暫休息。
又或許我們只需要想想許多員工在十分鐘休息時做的事情。我的專業經驗告訴我,許多上班時短休的員工都聚在建築物入口外面一起吸菸(製造出一片煙霧,讓其餘的人必須走過煙霧才能進出建築物)。我的進一步推論是,導致癌症的有可能是香菸而不是短休。這個例子是我編造出來以凸顯其荒謬,但是我向你保證,許多真實生活中的統計惡行一經解構幾乎就是這麼荒謬。
這不是一本教科書,因此涵蓋的主題範圍及說明的方式比較隨意。這本書意在以最生活化的方式來介紹統計觀念。科學家如何判定致癌因素?民調如何進行(哪些地方會出錯)?誰「拿統計騙人」,他們如何做到的?你的信用卡公司如何利用你的購物內容數據,來預測你是否會錯過繳費期限(他們真的做得到)?
如果你想要了解新聞背後的數字及欣賞數據神奇的力量,這本書正符所需。最後,我希望能說服你相信瑞典數學家及作家唐克爾斯的創見:用統計說謊很容易,沒有統計要找出真相卻很困難。
但我還有更大膽的期望,我認為你說不定會喜歡上統計,它背後的想法既絕妙有趣也十分實用,關鍵就在於將重要的概念從難解的技術細節中分離,不要讓它們妨礙你,這就是《聰明學統計的13又½堂課》。
- 為什麼要學統計?
- 誰是史上最佳球員?—描述性統計
- 「他的個性還不錯」及其他非謊言但嚴重誤導的敘述—誤導式統計
- 線上租片公司怎麼會知道我喜歡什麼電影?—相關性
- 不要為99美元的印表機加買延長保固—機率入門
- 5又½. 門後會是一隻羊,還是你企盼的獎品?—蒙提霍爾問題
- 看看過度自信的數學怪咖如何差點摧毀全球金融系統—機率的問題
- 「垃圾進,垃圾出」—數據的重要性
- 統計學的詹姆斯大帝—中央極限定理
- 為什麼統計學教授懷疑我作弊?—推論
- 我們如何得知64%的美國人支持死刑(樣本誤差為正負3%)—民調
- 奇蹟仙丹—迴歸分析
- 強制警告標示—常見的迴歸錯誤
- 就讀哈佛會改變你的一生嗎?—方案評估
為什麼學統計?

2014 Gini Index World Map, income inequality distribution by country per World Bank
via wiki
「基尼指數」(Gini coefficient)是經濟學上用來測量貧富不均的標準工具。它是用來將複雜的資訊濃縮成單一數字的方便工具,它具有大多數描述性統計的優點,也就是它提供一個容易的方法,可用來比較兩國的收入分配狀態,或是單一國家在不同時期的收入分配狀態。基尼指數是從0到1的差距內,測量一個國家的財富或收入分配程度,這數字可用來計算財富或是年收入,還能夠以個人或每戶為單位來計算(這些統計數字都高度相關,但並不完全一致)。它沒有真正的意義,只是用來比較的工具。如果一個國家的每戶財富都一樣,基尼指數就會是0。相對的,如果一個國家的財富都集中在一戶人家之中,它就會是1。因此,當國家的財富分配越不平均,基尼指數就會越接近一。根據中央情報局的資料,美國的基尼指數是0.45。有時候,基尼指數會被乘上一百,讓它成為整數,美國的基尼指數在這時就是45。
基尼指數當然不會是衡量財富不均程度的最佳方式,但它以一個簡便的形式,提供我們一些社會重要現象的重要資訊。
《紐約時報》(The New York Times):「數據只是知識的原料。」學統計是著眼於統計可以幫助我們處理數據,數據其實只是一個用來稱呼資訊的名詞。有時候數據在事情的全貌上微不足道,例如運動比賽的統計;有時候由數據則能洞察人類現象的特性,正如基尼指數。
描述性統計本身有簡化的目的,因次也意味著會失去一些差異和細節。這也表示,過度依賴任何描述性統計可能會誤導結論。
統計學的一項重要功能,就是針對無法取得全部資訊的大問題,利用我們擁有的數據做出知性的判讀。我們利用「已知世界」的數據,對「未知世界」做出知性的結論。
統計的目的就是要學習那些會影響生活的事情。
迴歸分析是一種工具,可讓研究人員在保持(或「控制」)其他重要變數(如飲食、運動、體重等)的作用不變的情況下,將兩個變數之間(如吸菸與癌症)的關係分離出來。
但我們雖可利用統計分析分離出兩個變數中的強烈關聯,卻未必能解釋這種關聯為何存在。在某些情況下,我們也無法確知這種關聯是有因果作用的,亦即一個變數的改變真的能引起另一個變數的改變。
那麼,學統計的目的何在?
- 將巨量資料做出摘要。
- 做出較好的決定。
- 解答出重要的社會問題。
- 辨識出能提升做每一件事效果的模式,從賣紙尿布到抓罪犯皆然。
- 糾出作弊者及起訴罪犯。
- 評估政策、計畫、藥品、醫療過程與其他創新事項的效用。
- 發現那些利用這些強有力的工具達到邪惡目的的惡棍。
描述性統計
我們當然希望在一項調查中,獲得所有的資訊,但諷刺的是,愈多的數據往往愈不清晰,我們利用運算把一連串的數據減少到幾個數字來描述。這些描述性統計給我們一個容易處理且有意義的摘要,可以一窺根本現象的全貌。但是,任何簡化都會引致濫用,描述性統計就像是網路交友的個人簡介,技術性方面都很正確,卻很容易誤導。
第一項描述性工作通常是去找到一組數據的「中間量數」,也就是「集中趨勢」。一個分配最基本的「中間量數」是平均數,但平均數容易被「偏離值」扭曲,偏離值是指遠離中心的觀察值。因此,我們有另一個統計數字可以代表一個分配的「中間量數」,就是「中位數」,中位數是將一個分配區分成兩半的那個點,代表一半的觀察值位於中位數的上方,另一半在下方。
平均數和中位數都不難算出,關鍵在於在特定情況下,需要決定哪一個「中間量數」比較正確。
這類描述型統計說明了一個特定的觀察值與其他觀察值比較時的位置。
另一個有助於我們在一堆雜亂數字理出頭緒的統計值是標準差,它是用來衡量數據以平均值為中心時,是如何分布的,也就是所有觀察值的範圍有多廣。標準差這個描述性統計值給我們一個數字,反映出觀察值在平均值周遭的分布情形。
變異數是將每一個觀察值與平均值之間的差平方,再將這些差平方數的總和除以觀察值的數目。因為每一觀察值與平均值之間的差都被平方,也意味著變異數的公式將較大的權重置於落在離平均值較遠的觀察值,亦即偏離值。
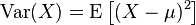
許多典型的數據中,會有高比例的觀察值落在平均值的一個標準差之內。
常態分配是統計學上最重要、最有用且最普遍的分配之一。常態分配的數據是以對稱的方式圍繞著平均值,形成你所熟悉的鐘型。
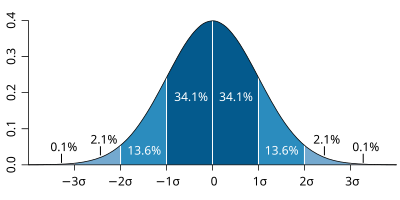
via wiki
常態分配之美來自一個事實,就是我們準確地知道,觀察值中落在平均值的一個標準差之內(68.2%)、兩個標準差之內(95.4%)、三個標準差之內(99.7%)等的比例各為多少。平均值是一條中線,通常以μ來代表,標準差則以σ代表。每一波段代表一個表準差。

2014 Human Development Index
via wiki
「指數」把許多複雜的資訊整合成一個單一數字,就可以將本來無法簡單比較的東西加以排序。然而,把許多複雜的資訊整合成單一數字也正是指數的缺點。有無數的方法可達到這個目的,每一種都可能產生不同的結果。任何指數對於整合其各項統計值都高度敏感,對各項統計值所占的權重也很敏感,因此指數可以是有用卻不完美的工具,也可以是用來蒙騙的工具。
「聯合國人類發展指數」(Human Development Index)是用來衡量經濟福祉的數值,要比國民所得來得周全。國民所得是構成「聯合國人類發展指數」的項目之一,但這指數還包括平均餘命及教育程度的測量值。以每人經濟產出來計算,美國在全球位居十一,但在人類發展方面則位居全球第四。如果將「聯合國人類發展指數」的組成項目重新編排的話,排名的確會稍微變化,但是也不至於讓辛巴威的名次超越挪威。這是個用來快速一覽全球生活水準的便利且不失正確的工具。
描述型統計有助於表達議題,而針對議題該做什麼,則是意識形態與政治問題。
誤導式統計
任何對約會有過仔細觀察的人都知道,「他的個性還不錯」這句話通常會讓人有所警覺,不是因為這樣的描述一定有問題,而是因為沒有說出來的事實可能是這個傢伙有前科,或者他的離婚尚未生效。我們不懷疑這傢伙的個性好,但擔心的是「個性還不錯」這個真實敘述被用來遮掩或模糊其他資訊,造成嚴重誤導。
統計也是如此。統計的範疇奠基於數學,數學是門精確的學問,但使用統計來描述複雜的現象卻是不精確的,會留下許多遮蔽事實的空間。
“There are three kinds of lies: lies, damned lies, and statistics.”「精確」是指我們表示某件事的準確性;「正確」用來衡量一個數字是否大致符合真相,因此精確性與正確性會有混淆的危險。如果一個答案是正確的,那麼愈精確通常愈好;但是再怎麼也無法取代正確性。事實上,精確性都可能給我們一種錯誤的確定感,因而遮掩其不正確性。
——Mark Twain
即使最精確的測量或計算,都應該經過常識的判斷。分析單位是統計學上用來比較的實體,但不同的分析單位所帶來的統計意義可能截然不同。
《經濟學人》指出:「如果你考量的是人民,而不是國家,那麼全球不均的現象正迅速減輕。」
在前面就提過的,平均數與中位數同樣會造成誤導。中位數的特色,在於它不強調觀察值落在離中間點多遠之處,而是觀察值落在中間點的上方或下方,因為它沒有平均數對偏離值的高敏感性,因此會有遮掩作用。平均數則受到觀察值分布形態的影響。從講求正確的觀點而言,平均數與中位數圍繞的問題重點是,一個分配的偏離值是否扭曲,亦或反而是全貌中重要的一部份。當然,任何周全的統計分析很可能兩者都會呈現,如果只有出現中位數或平均數,也許是為了精簡,也有可能是某人想用統計值來「說服」別人。
1980年由Harold Ramis執導的電影《瘋狂高爾夫》(Caddyshack)裡,有這麼一段對話:
「你打幾桿?」同樣的,在比較各年代的幣值時,會因為通貨膨脹有所差異,在美國國內史上的票房及銷售總收入榜就會看出差距,這些賣座電影並未經過通貨膨脹的調整。經濟學家有專門的名詞來稱呼是否經過通膨調整的幣值,「名目幣值」代表未經通膨調整,「實質幣值」則是經過通膨調整的數字。
「哦,我沒怎麼記。」
「那你怎麼和別人比較?」
「比身高啊。」
統計的一個重要角色是用來描述數量隨著時間的變化。我們通常用百分比來表示這些變化,因為可以獲得規模與背景的概念。百分比雖不會說謊,卻可能誇大,其中一個手法是運用百分比的變化來描述比較基數非常低的變化。
一項統計指標會存在任何描述性統計的所有潛在陷阱,還要加上因為結合多項指標而形成單一數字導致的扭曲。依照指標的定義,它應該對構成的因素都有敏感度,會受到形成指標的各個衡量因素,及每個因素的權重的影響。
就如「人類發展指數」而言,在一個與平均國民所得相關的指數裡,應該如何計算一個國家識字率的權重?
濃縮許多指標形成單一數字帶來的簡易性,是否過於著重過程中既有的失真性?有時答案可能是否定的。
統計惡行非關數學好壞,如有任何關連,那就是厲害的計算可以模糊邪惡的動機,你正確無誤地算出平均數這件事,並不會改變中位數是更正確的指標這個事實,令人驚訝的是,判斷與誠實反而重要得多。對統計學知之甚詳未必會轉變錯誤的行為,就像對法律知之甚詳未必會轉換為犯罪行為。
相關性
相關性用來衡量兩個現象彼此關聯的程度。例如,夏天氣溫與冰淇淋的銷售之間有相關性,氣溫上升,冰淇淋的銷售就上升。如果兩個變數之間朝相同的方向變化,這就是正向相關,就像身高和體重之間的關係。反之,就是負向相關,就像運動和體重之間的關係。
這類關聯的棘手之處在於並非每種觀察直都符合這個模式,有時候矮的人體重大於高的人;有時候不運動的人比一天到晚都運動的人來得要瘦;然而,身高與體重、運動與體重之間還是有顯著的關係。
另外,所謂「統計顯著性」,其概念是由分析發現兩個變數之間有某種關聯,而這種關聯不太可能因為湊巧而發生。
相關性的力量在於,我們可以用單一的描述性統計來代表兩變數之間的關聯,也就是相關係數。
相關係數有兩個迷人的特質。第一個特質 ,它是一個介於-1與1之間的單一數目。相關係數是1的連結往往被形容是完美的相關,代表一個變數的每個變化與另一變數朝相同方向產生完全相等的變化之間有關連。反之,相關係數是-1的連結則是完美的負相關,代表一個變數的每個變化與另一個變數朝反方向產生完全相等的變化之間有關連。相關係數愈接近-1或1,關聯性愈強。相關係數是0或接近0,則代表兩者之間沒有顯著的關係。
第二個特質是,它沒有單位的限制。例如身高是以公尺為單位,體重則以公斤為單位,但兩者之間還是可以計算它們的相關係數。
相關係數就像個奇蹟,它將一堆錯綜複雜、單位不同的數據濃縮成單一、漂亮的描述性統計值。

Pearson product-moment correlation coefficient
via wiki
如果一個變數離平均值的距離大致符合另一個變數離其平均值的距離(像樣本人口的身高離平均身高往上或往下都很遠,其體重大致離平均體重的同一方向也很遠),就會預期兩個變數之間有強烈正相關。反之(如樣本人口的運動時間離平均運動時間多得多,其體重大致離平均體制少得多),就會預期兩個變數之間有強烈負相關。
但有個至關緊要的重點,那就是相關性並不意味著因果關係。
兩變數間正向或反向的關聯,未必代表一個變數的改變會引起另一個變數的改變,例如學生SAT成績與家中電視機的數目可能呈現正向關係,但這並不表示父母多買幾台電視機擺在家中後,小孩的成績就會因此暴升,當然也不表示花很多的時間看電視有利於學業。
這樣的相關性最合理的解釋是,教育程度高的父母買得起較多台電視,他們小孩的測驗成績也傾向比平均成績比較好,電視機的數目與測驗成績之間的變化可能是因為第三個變數造成的,也就是父母的教育程度。根據大學委員會的數據,家庭收入超過二十萬美元的學生,SAT數學平均是586,相較之下,家庭收入等於或少於二十萬美元的學生,SAT數學平均成績是460。另外,收入超過二十萬美元的家庭住處的電視機數目也很可能多過收入等於或少於\二十萬美元的家庭。
The Pragmatic Theory solution to the Netflix Grand Prize
機率
機率是研究牽涉到不確定因素的事件及結果的學問。
「大數法則」這個重要的定律告訴我們,隨著試驗次數增加,結果的平均值會愈來愈接近期望值。
對於牽涉到在不同時間點會發生許多偶發事件的複雜情況,期望值可以幫助我們化繁為簡,做出決定。
一株決策樹可以有助於組織這類資訊,如果每一個結果相關的機率正確無誤,還可讓你得到可行性評估。決策樹列出每個不確定因素來源及跟每個可能結果相關的機率。在樹的末端會給我們所有可能的報酬與其各自的機率,如果將每一報酬乘上其可能性,再將所有可能性加總,就會得到這項投資的期望值。
機率是供我們對付生活中不確定性的工具。你不應該玩樂透;如果你預備長期投資,就應該投資股市(股票通常具有最佳的長期投資報酬率);你應該為某些情況買保險,除此之外無須購買。
「蒙提霍爾問題」(Monty Hall problem)是電視遊戲節目《讓我們做個交易》中跟機率有關的著名難題。每天節目結尾會邀請一名參賽者,和主持人蒙提一起站在三扇大門前:一號門、二號門,以及三號門。蒙提會向參賽者解釋有一扇門後是眾所期盼的獎品,另外兩扇門後則是一隻羊。參賽者挑選一扇門,就會獲得門後的獎品。
獲勝的機率在一開始是直截了當的。有兩隻羊和一輛車。參賽者和蒙提一起面對三扇門時,他有三分之一的機會選到的是一輛車。但這個節目有點變化,當參賽者選了一扇門之後,蒙提會打開參賽者沒有選的兩扇門之中的一扇,後面永遠都是一隻羊。這時蒙提會問參賽者要不要改變心意,從他原先選擇的那扇關著的門,換到另下另一扇關著的門。
參賽者應該換門嗎?
答案是應該。參賽者如果堅持原來的選擇,有三分之一的機會贏得大獎,轉換選擇則有三分之二的機會。
答案在於,蒙提清楚每扇門的後面是什麼。
如果參賽者選擇一號門,門後是一輛車,蒙提可以打開二號或三號門,後面都是一隻羊。
如果參賽者選擇一號門,車子是在二號門後,蒙提就會打開三號門。
如果參賽者選擇一號門,車子是在三號門後,蒙提就會打開二號門。
在一扇門打開後改變選擇,參賽者就有了兩個選項而非只有一個選項的好處。
假設遊戲規則稍微修改,參賽者一開始仍比照原來的方式,在三扇門中選擇一扇;但是接下來在任何一扇門打開出現一隻羊之前,蒙提會先說:「你願不願意放棄原來的選擇,改選那兩扇你沒選擇的門?」
這並非是一個很難的決定,你顯然應該放棄而改選另外兩扇門,那會讓你獲勝的機率從三分之一增加到三分之二。基本認知是,如果你可以選擇兩扇門,無論如何兩扇中都有一扇後面一定是羊,當他問你是否改變心意前就打開一扇後面是羊的門,他等於是在幫你一個大忙。
因此擬在下面兩個情況贏得大獎的機率是相同的:
- 選擇一號門,而在任何一扇門打開前,同意改選二號或三號門。
- 選擇一號門,而在蒙提打開三號門出現一隻羊後改選二號門(或在蒙提打開二號出現一隻羊後改選三號門)。
《紐約時報》專欄作家喬·諾切拉曾概述尼古拉斯·塔雷伯的看法:「最大的風險從來就不是你所能預見和衡量的,反而是你無法預見,因此也絕不可能衡量的,它們是那種看似遠在正常發生機率之外,以至於你無法想像會發生在你有生之年的風險,它們的確會發生,而且是比你願意知道的更常發生。」
現實是,沒有什麼人會著墨於「末端風險」(名稱來自統計分配圖的兩個末端),那個可能帶來災難性結果的小風險。
錯估這些風險可能是犯了幾種基本錯誤:首先,我們混淆了精確性與正確性,錯誤的精確性導致人們相信他們掌控著風險,事實上卻沒有。其次,潛在機率的估計不正確。第三,忽視了「末端風險」,那些被認為幾乎不可能的事還是會發生,事實上,經過一段夠長的時間,它們甚至不會如此不可能發生,就像世界上一直都有人被雷擊中,也總有人中樂透頭彩。
機率提供一套強而有用的工具,使用得當可以了解世界,使用不當則會造成巨大混亂。
「機率不會犯錯,是應用機率的人犯錯。」下列有一些和機率有關的普遍錯誤、誤解,以及道德困境:
- 當事件並不是「獨立事件」時,卻假設它們是。
- 當事件屬於「獨立事件」時,卻未能發現。
- 群集的確會發生。
- 你可能會在報上看過這樣的資料:在某一特定地區有一群數目不合常理的人都罹患某種罕見的癌症,那一定是因為水質或當地發電廠,或手機基地台。當然,這些因素美一樣都可能引發健康問題,但在這種病例的聚集也可能純粹是偶發關係。當我們看到諸如此類異常事件的發生,,卻沒看到發生的背景,就會假設一定是有不湊巧的因素。
- 檢方的謬誤。
- 假設你在法庭上聽到下列結果的證詞:一、犯罪現場找到的DNA樣本與被告DNA樣本相符;二、犯罪現場找到的DNA樣本與被告以外的人的DNA樣本相符的機率只有百萬分之一。基於這些證據,你會不會認定被告有罪?
- 當統計證據的背景故事被忽略時,就會發生檢方的謬誤。
- 均值迴歸。
- 你也許聽過《運動畫刊》詛咒,個別運動員或運動團隊只要登上畫刊封面,接下來的成績就會下滑,有個解釋是,登上該雜誌封面會對接下來的表現有不利影響。統計學上合理的解釋是,團隊及運動員在一連串表現傑出異常的時期後登上封面,接下來的表現只是回歸正常,或是平均現象,這是所謂均值迴歸現象。機率告訴我們,任何偏離值離──平均值兩端特別遠的觀察值──的後面都可以跟著與長期平均值更一致的效果。
- 馬麥迪爾與泰德寫道:「我們的研究結果顯示,媒體引發的超級巨星文化所導致的行為扭曲超過均值迴歸現象。」
- 統計歧視。
- 何時可以根據機率顯示可能發生的結果來採取行動?什麼時候又不宜呢?
- 我們每天都得到愈來愈多事情的各類資訊,如果數據指出我們對的時候比錯的時候更多,是不是就可以產生歧視呢?用來判定購買鳥飼料的人比較不會付信用卡費用這類分析,也可以用在生活中的每個地方。到什麼程度是可以接受的呢?如果我們建立了一個模式,在一百次裡有八十次可以正確辨識出毒品走私者,那剩下百分之二十的傢伙會如何──因為我們的模式會一而再、再而三地騷擾他們。
- 不論機率有多簡練與精確,都不能取代我們必須考量要做的是何種計算,及我們為什麼要做。
數據的重要性
數據之於統計正如同一個好攻擊鋒線之於明星四分衛。每個明星四分衛的前面都有一群好的阻擋球員,他們通常不會得到太多功勞,但沒有他們,就沒有明星四分衛。
通常數據要能達到三個條件之一。首先,我們要求數據樣本能代表某個較大群體或母體。如果我們打算評估選民對某個特定政治候選人的看法,就需要訪問一些潛在選民樣本,這些選民足以代表相關選區的所有選民。統計最有力的發現之一,是從適當選取、規模合理的樣本中獲致的理論,可能就跟嘗試從整個母體獲致的同類資訊完全相同。
從一個較大的母體取得代表性樣本最容易的方式,就是雖機選擇那個母體裡的一些子集合。這個方法的關鍵在於相關母體裡的每個觀察值都必須有相同的機會被包括在樣本裡。
民調公司與市場研究公司承天都在思考如何以最具成本效益的方式,在各種母體中得到具有代表性的數據。現在應該思考幾件重要的事情:
- 樣本具有代表性是一件極其重要的事情,因為它會打開大門,讓你用到一些統計學最強力的工具。
- 獲得好的樣本知易行難。
- 許多事態嚴重的統計結果推論,是將好的統計方法應用在壞樣本造成的,而非反過來。
- 規模很重要,愈大愈好。
第二個條件是數據能提供一些比較的來源。新藥物是否比目前的治療更有效?接受職業訓練的更生人是否比未接受者較不容易回到監獄?上私立學校的學生是否比上公立學校的學生表現得更好?
在這些例子,我們的目的是要找出兩組條件大略相似,只是接受我們所關注的「處理」不同的受試者。在社會科學理,「處理」這個字的範圍含括從性行為受挫的果蠅到接受所得稅退稅都是。就像任何其他科學方法的應用,我們想要分離出某個特定措施或特質的影響,這就是果贏實驗的天才之處,研究人員想出產生控制組(交配過的雄果蠅)與處理組(被拒絕的雄果蠅)(處理組亦常被稱為實驗組)的方法,接下來其飲食行為的不同就能歸因於是否在性行為上被拒。
以人類為受試者反覆面臨的一向研究挑戰,是所產生的實驗組與控制組之間「唯有其中一組」得到處理,另一組則否。因為這個原因,做研究時的「黃金準則」就是隨機化。在過程裡,人類受試者必須隨機被指派到實驗組或控制組。我們不會假設所有實驗受試者都完全一樣,而是假設隨機化會均衡地劃分兩組之間相關的特質──不單是我們可以觀察到的特質,例如種族或收入,還包括無法衡量或未曾考慮的複雜特質,例如毅力或信心。
第三個是,有時候我們對於拿到的資訊沒什麼特別的想法,但是認為到了某個時候就會派上用場。如果我們能準確地知道哪些是有用的,可能一開始就不用調查了。
縱向研究室諄對一大組群的對象在許多不同時間點蒐集資訊,譬如兩年一次,當探討需要數年或數十年才能獲知因果關係時,這種數據就顯得特別珍貴。
橫斷面數據集,就是在單一時間點蒐集的證據。比方說,流行病學家在尋找一種新疾病的起因時,他們或許會從所有已感染的人身上蒐集資料,希望找出某種能溯至源頭的模式。他們吃過什麼?去過哪裡旅行?有什麼共同點?研究人員還可能蒐集沒被感然的人的資料,以突顯兩個族群之間的對比。
以下是一些常見的數據使用不適當的案例:
- 選樣偏差
- 如何選出評估的樣本?如果相關母體的每一分子被選入樣本的機會並不均等,從該樣本獲致的結論就會有問體。選樣偏差會以許多其他方式出現。調查機場消費者會有的偏差是,旅行的人可能比一般大眾富裕;在九十號州際公路休息站的調查面臨的則可能是相反的問題。兩項調查還可能有一個共同的偏差,那就是願意在公共場所回答調查的人,不同於那些不願被打擾的人。
- 每當個別自願者出現在實驗組的時候,就會產生一種相關的偏差來源,稱之為自我選樣偏差。譬如說,自願參加戒毒治療的犯人不同於其他人,因為他們是自願加入戒毒計畫的,如郭這些參與者在出獄後較其他犯人不易再入獄,那當然很好,但對這了解這項戒毒計畫的價值完全沒有助益。我們無法將一個因素的因果影響與另一個人切割。
- 刊登偏差
- 正面的發現比負面的發現較可能被刊登,因而可能扭曲我們看到的結果。這種現象的最終效應就是曲解我們看到或沒看到的研究。統計學裡有一個一再浮現的重要觀念是,不尋常的事情每隔一陣子就會出現一次,純粹是機會的緣故。如果你進行一百項研究,其中可能會有一項的結果十分荒謬,例如玩電動遊戲與較低大腸癌罹患率之間的統計關聯。問題是:那些九十九項發現電腦遊戲與大腸癌之間沒有關係的研究不會被刊登,原因是這樣的內容不夠有趣。唯一一個確實發現有統計關聯的研究會被刊登出來,然後得到大量關注。這種偏差不是來自研究本身,而是來自大眾實際接受到的扭曲資訊。
- 回憶偏差
- 記憶是個迷人的東西,雖然未必都是漂亮數據的最佳來源。我們會有一種自然的人性衝動,認為現在就是過去發生的事合理結果,亦即所謂的因果關係。問題是當我們試著解釋在某一特別好或不好的結果時,記憶往往變得「系統性失靈」。以一個探討飲食與癌症關係的研究為例,一九六三年有一位哈佛學者彙集一個數據集,包刮一組罹患乳癌的女性及一組年齡相當未被診斷罹癌的女性,兩組女性都被問到早年的飲食習。研究產生明確的結果:罹患乳癌的女性明顯可能在年輕時較常食用高脂肪食物。
- 但這實際上並不是調查如何影響罹癌可能性的研究,這是一個調查罹癌如何影響女性對她早年飲食記憶的研究。所有受調女性數年前在任何一位被診斷出罹癌之前,已經做過一份飲食調查,結果是,罹患乳癌的女性在自己的飲食記憶中食用的脂肪比實際實用的高得多。
- 回憶偏差是縱向研究比橫斷面研究更受偏愛的原因之一。在縱向研究裡,蒐集的是訪問當時的數據資料。受調者五歲時會被問到他當下對學校的心態,十三年後我們可以再度受訪同一位受調者,判斷他是否已經自高中輟學。在橫斷面研究裡,所有的資料都是在某一個時間點上蒐集的,我們必須問一名十八歲高中中輟生在五歲時對學校的感覺,這種資料在本質上就不太可靠。
- 存活者偏差
- 假設有一位中學校長報告:具有某種特性的學生群連續四年考試成績都穩定提升。這一班二年級的成績較其一年級時好,三年級時更好,四年級時是最好的。我們假設沒有作弊行為,甚至沒有將描述性統計做任何創意的運用,從每一個可能的指標來看,無論是平均數、中位數、學生成績及格比率等,每一年這一群學生的成績都比前一年好。
- 當有一些或許多觀察值從樣本排除後,剩餘樣本組合已遭改變,乃至於會影響任何分析的結果。假設這位校長真的很糟,每年有一半的學生退學,這就可能大大美化學校的測驗成績,即使沒有任何一名學生的測驗成績變得更好。
- 健康使用者偏差
- 固定服用維他命的人可能比較健康──因為他們是那種會固定服用維他命的人!維他命對健康是否有影響是不同的問題。思考下面這個想像的實驗,假設公共衛生官員提倡一個理論,所有新手爸媽應該讓孩子穿著紫色睡意睡覺,因為有助於刺激孩童大腦發育。二十年後,縱向研究證實從小穿紫色睡衣的確和日後成就有極大的正面關聯。
- 當然,紫色睡衣並不重要;重要的是擁有那種會要小孩穿紫色睡衣的父母。即使我們試著控制如父母教育之類的因素,在那些執著於要小孩穿紫色睡衣的父母與不會如此做的父母之間,還是會有我們觀察不到的差異。
中央極限定理
對許多運用一組樣本來為廣大母體作出推論的統計活動而言,中央極限定理就是「電源」。
中央極限定理所根據的核心是:一個龐大、適當選取的樣本會近似它所來自的母體。樣本與樣本之間顯然會有差異,但是任一樣本與其母體大不相同的機率則很低。
- 如果我們擁有某一向母體的詳細資訊,就可以針對自那個母體適當抽選的樣本做出有力的推論。假定一個學校校長擁有期學校所有學生標準測驗分數的詳細資料,亦即相關的母體。現在,假設那個學校所屬學區的官員下星期將來學校,給一百名隨機選取的學生類似的標準測驗。這一百名樣本學生的成績,將會用來評估學校整體的成績。根據中央極限定理,這一百名隨機選取學生樣本的平均測驗分數,通常不會偏離整體學生平均測驗分數太遠。
- 如果我們擁有某一適當抽取樣本的詳細資訊,就可以針對樣本的母體做出準確得嚇人的推論。這個推論的方向和上個例子相反,是將我們放在學區官員的位置上,來評估學區各個學校的表現。不同於學校校長,官員沒有校長手中其學校所有學生的標準測驗資料,亦即相關母體。他將在每間學校隨機選取一百名學生,進行一項類似的測驗。這位官員仍可合理確定,僅憑著一百名學生樣本的測驗分數,就可以公平評估該學校整體成績。樣本結果很足以代表全部母體的結果。
如果第一點是真的,第二點也就一定是真的,反之亦然。
- 如果我們有描述某一特定樣本的資料,也就是描述某一特定母體的資料,就可以推論,該特定樣本是否與可能出自特定母體的樣本一致。中央極限定理讓我們得以計算一個特定樣本是從一個特定母體中選取出來的機率。若機率很低,我們就有高度信心判斷這個特定樣本不是從那個特定母體中選取出來的。
- 如果我們知道兩個樣本的基本特色,就可以推論其是否可能選自同一母體。
中央極限定理讓我們更進一步,預測哪些不同的樣本平均數會聚集在母體平均數的附近。母體的分配形狀如何無關緊要,其樣本平均數的分配不會偏斜。樣本的數目愈大,分配形狀就會愈接近常態分配。
